Rough Set Theory dan Data Mining
Teori rough set adalah sebuah teknik matematik yang dikembangkan oleh Pawlack pada tahun 1980.
Teknik ini digunakan untuk menangani masalah Uncertainty, Imprecision dan Vagueness dalam aplikasi Artificial Intelligence (AI).
Ianya merupakan teknik yang efisien untuk Knowledge Discovery in Database (KDD) proses dan Data Mining.
Secara umum, teori rough set telah digunakan dalam banyak applikasi seperti medicine, pharmacology, business, banking, engineering design, image processing dan decision analysis.
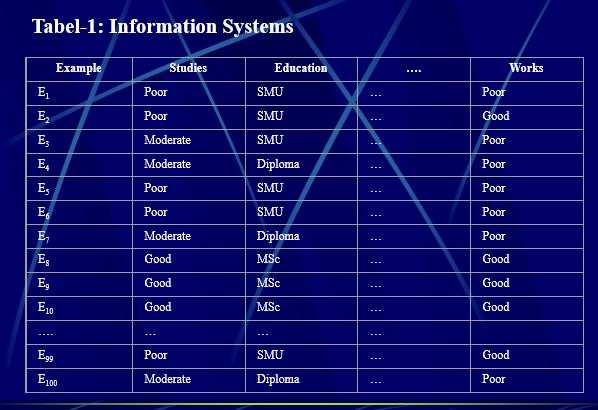
Rough set menawarkan dua bentuk representasi data yaitu Information Systems (IS) dan Decision Systems (DS). Definisi Information Systems: Sebuah Information Systems (IS) adalah pasangan IS={U,A}, dimana U={e1, e2,…, em} dan A={a1, a2, …, an} yang merupakan sekumpulan example dan attribute kondisi secara berurutan. Definisi diatas memperlihatkan bahwa sebuah Information Systems terdiri dari sekumpulan example, seperti {e1, e2, …, em} dan attribute kondisi, seperti {a1, a2, …, an}. Sebuah Information Systems yang sederhana diberikan dalam table-1.

Dari tabel diatas dicari nilai record yang studies,education, works nya sama dari e1 sampai e100. didapat equivalence class:
E1,E5,E6
E2,E99
E3,
E4,E7,E100
E8,E9,E10
SETELAH ITU BARU MASUK KE TABEL Equivalence Class Tabel-2 memperlihatkan sebuah Decision Systems yang sederhana. Ianya terdiri dari m objek, seperti E1, E2, …, Em, dan n attribute, seperti Studies, Education, …, Works dan Income (D). Dalam tabel ini, n-1 attribute, Studies, Education, …, Works, adalah attribute kondisi, sedangkan Income adalah decision attribute.
 Kemudian tahap selanjutnya
Kemudian tahap selanjutnya
Discernibility Matrix

Reduct:
{A,C} = {Studies, Works}
{B,C} = {Education, Works}
{A} = {Studies}
{B} = {Education}
Menghasilkan knowledge/rule dng menggunakan hasil reduct dan tabel decision system {studies, works}
if studies=poor and works=poor then income=none
if studies=poor and works=good then income=low
if stuide=moderate and works=poor then income=low
if studies=good and works=good then income=medium or income=high
Begitu juga seterusnya dengan no 234 .
Cek dari data tabel awal untuk mengisi ini semua dengan menggunakan atribuat atau fielndya saja . Kalau barisnya sama isinya maka hanya 1 aj yg mewakili gk perlu semua. Namun jika hasil kepeutusanya incomenya beda ditambahkan aja or di then nya gun.
Keterangan dari hasil roseta
"if studies=poor and works=poor then income=none
LHS Support adalah bagian kiri yaitu if studies=poor and works=poor
RHS support adalah bagian kanan yaitu then income=none
RHS Accuracy =RHS Support / LHS Support
LHS Coverage =LHS Support / n-jumlah objek (12) 3/12=0.25
RHS Coverage = RHS Support / n-jumlah yang memenuhi bagian then lownya ada 6 jd 2/3=0.33
RHS Stability = RHS Support / n-jumlah yang memenuhi bagian thennya none=3 jadi 3/3=1
LHS Length = Jumlah Value pada bagian If
RHS Length = Jumlah Value pada bagian Then

Rough set menawarkan dua bentuk representasi data yaitu Information Systems (IS) dan Decision Systems (DS). Definisi Information Systems: Sebuah Information Systems (IS) adalah pasangan IS={U,A}, dimana U={e1, e2,…, em} dan A={a1, a2, …, an} yang merupakan sekumpulan example dan attribute kondisi secara berurutan. Definisi diatas memperlihatkan bahwa sebuah Information Systems terdiri dari sekumpulan example, seperti {e1, e2, …, em} dan attribute kondisi, seperti {a1, a2, …, an}. Sebuah Information Systems yang sederhana diberikan dalam table-1.
CARA PENYELESAIAN
Dari tabel diatas dicari nilai record yang studies,education, works nya sama dari e1 sampai e100. didapat equivalence class:
E1,E5,E6
E2,E99
E3,
E4,E7,E100
E8,E9,E10
SETELAH ITU BARU MASUK KE TABEL Equivalence Class Tabel-2 memperlihatkan sebuah Decision Systems yang sederhana. Ianya terdiri dari m objek, seperti E1, E2, …, Em, dan n attribute, seperti Studies, Education, …, Works dan Income (D). Dalam tabel ini, n-1 attribute, Studies, Education, …, Works, adalah attribute kondisi, sedangkan Income adalah decision attribute.

Discernibility Matrix

Discernib Matrix
Dari hasil reduction maka dapat dihasilkan yang detail dan yang sudah ada hasil pada reduct akan dimabil salah satu saja jadi sebagai berikut:Reduct:
{A,C} = {Studies, Works}
{B,C} = {Education, Works}
{A} = {Studies}
{B} = {Education}
Menghasilkan knowledge/rule dng menggunakan hasil reduct dan tabel decision system {studies, works}
if studies=poor and works=poor then income=none
if studies=poor and works=good then income=low
if stuide=moderate and works=poor then income=low
if studies=good and works=good then income=medium or income=high
Begitu juga seterusnya dengan no 234 .
Cek dari data tabel awal untuk mengisi ini semua dengan menggunakan atribuat atau fielndya saja . Kalau barisnya sama isinya maka hanya 1 aj yg mewakili gk perlu semua. Namun jika hasil kepeutusanya incomenya beda ditambahkan aja or di then nya gun.
Keterangan dari hasil roseta
"if studies=poor and works=poor then income=none
LHS Support adalah bagian kiri yaitu if studies=poor and works=poor
RHS support adalah bagian kanan yaitu then income=none
RHS Accuracy =RHS Support / LHS Support
LHS Coverage =LHS Support / n-jumlah objek (12) 3/12=0.25
RHS Coverage = RHS Support / n-jumlah yang memenuhi bagian then lownya ada 6 jd 2/3=0.33
RHS Stability = RHS Support / n-jumlah yang memenuhi bagian thennya none=3 jadi 3/3=1
LHS Length = Jumlah Value pada bagian If
RHS Length = Jumlah Value pada bagian Then

Comments
Post a Comment